
Le machine learning, c'est quoi exactement ?
Comme c’est le sujet qui me tient vraiment à cœur en ce moment, j’en parle beaucoup autour de moi. Et je me suis plusieurs fois rendu compte que mes interlocuteurs ne voyaient pas bien ce que c’était et à quoi ça servait concrètement. Comme cela fait maintenant deux mois que c’est mon pain quotidien, je vous propose donc un petit tour du machine learning : qu’est-ce que c’est ? A quoi ça sert ? Comment ça marche ?
Tout d’abord, voyons ce que wikipedia nous dit dessus :
Machine learning, a branch of artificial intelligence, concerns the construction and study of systems that can learn from data”
Wikipedia nous donne aussi la définition du machine learning selon Arthur Samuel :
Field of study that gives computers the ability to learn without being explicitly programmed
Ces deux définitions nous disent donc que le machine learning permet aux ordinateurs d’effectuer des tâches pour lesquelles ils ne sont pas explicitement programmés en apprenant avec des données. Autant quand on voit de quoi on parle, je trouve les définitions très claires, autant je comprends bien que si on ne connait pas du tout ce domaine, les choses peuvent paraître encore plus mystiques : “Je vais donner des chiffres à mon ordinateur et il va devenir intelligent ?”.
Si je devais expliquer en quelques mots ce qu’est le machine learning je dirais que c’est un domaine de l’informatique qui met au point des algorithmes permettant de déterminer pour de nouvelles données des caractéristiques à partir de la connaissance de données d’apprentissage. En quelque sorte, l’algorithme apprends des règles en se basant sur les données d’apprentissage et les applique à de nouvelles données. Cela se fait, entre autre, à l’aide de probabilités, de statistiques et de régressions.
Comprendre un peu mieux
Il existe deux grandes catégories de prédictions en machine learning : les régressions et les classifications. Pour les régressions ce que nous souhaitons prédire est une valeur numérique continue (par exemple, le prix d’un appartement) alors que pour la classification, on cherchera à déterminer une valeur discrète et finie (par exemple, à quelle espèce appartient une fleur). Pour pouvoir faire ces prédictions, les algorithmes effectuent des calculs plus ou moins complexes sur des valeurs numériques. Il est donc nécessaire de transformer les caractéristiques des éléments à analyser en un tableau numérique représentant ces caractéristiques (features). Cette étape est cruciale ! Afin d’obtenir de bonnes prédictions, il est nécessaire de rassembler toutes les caractéristiques importantes (pour le résultat qu’on souhaite établir) et de bien les modéliser. Par exemple, si on cherche à déterminer le prix de vente d’un appartement, il faudra probablement prendre en compte sa superficie, son emplacement, son entretien, s’il est meublé… Mais peut être aussi d’autres caractéristiques auxquelles on ne pense pas forcément au premier abord. Il est donc essentiel de très bien connaître le domaine métier pour pouvoir modéliser correctement les éléments que l’on souhaite traiter. Une fois toutes ces caractéristiques transformées en valeurs numériques, on peut appliquer un algorithme de machine learning à nos données pour pouvoir construire un modèle prédictif. Un algorithme très simple est par exemple de faire une régression linéaire sur les features des éléments. La valeur à prédire sera donc une combinaison linéaire des features. On peut aussi essayer des régressions logarithmique ou polynomiale mais il suffit simplement de créer de nouvelles features qui sont des fonctions des caractéristiques initiales pour pouvoir se ramener à une simple régression linéaire. Ce cas là est donc déjà relativement large.
Voici par exemple des données issues de seloger.com sur les prix des appartements dans le XXème arrondissement de Paris :
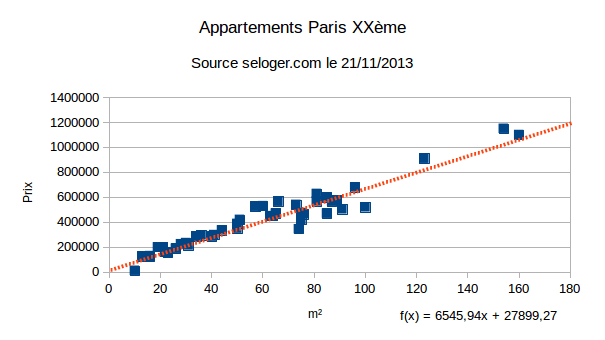
Comme on peut le voir, les prix suivent assez bien la droite déterminée par régression linéaire. On a donc probablement la caractéristique principale et déterminante. Si ce n’était pas le cas ou si l’on souhaite améliorer encore le modèle, on peut ajouter de nouvelles features. L’algorithme utilisé ici (régression linéaire) est le suivant :
class Predictor(a: Double, b: Double) {
def makePrediction(x: Double) = a * x + b
override def toString = "Predictor[y = " + a + " * x + " + b + "]"
}
def train(trainData: List[(Double, Double)]) = {
// y = a*x+b
var avgX, avgY = 0d;
for (data <- trainData) {
avgX += data._1;
avgY += data._2;
}
avgX = avgX / trainData.length
avgY = avgY / trainData.length
var avgXX, avgYY, avgXY = 0d;
for (data <- trainData) {
avgXX += (data._1 - avgX) * (data._1 - avgX);
avgYY += (data._2 - avgY) * (data._2 - avgY);
avgXY += (data._1 - avgX) * (data._2 - avgY);
}
val a = avgXY / avgXX;
val b = avgY - a * avgX;
new Predictor(a, b)
}
Pour ceux qui voudraient le tester par eux même ou ceux qui ont du mal avec Scala, voici le programme complet en Java et en Scala.
Une remarque très importante : il est nécessaire d’avoir des données représentatives de ce que l’on souhaite prédire. Par exemple, si l’on souhaite faire des prédictions pour des appartements de 300 m², le jeu de données présenté ici ne convient pas (tous les appartements ont une taille inférieure à 160 m²) et les prédictions faites seront potentiellement très mauvaises.
 Pour les classifications, l’exemple le plus connu est celui de la classification des iris où le but est de déterminer l’espèce d’un iris
à partir de la longueur et la largeur de ses pétales et sépales.
Comme le jeu de données est librement accessible et que c’est un très bon exemple, beaucoup de personnes l’utilisent pour leurs exemples ou leurs tests.
C’est un peu le “Hello world” du machine learning. Voici ce que donne une projection des données :
Pour les classifications, l’exemple le plus connu est celui de la classification des iris où le but est de déterminer l’espèce d’un iris
à partir de la longueur et la largeur de ses pétales et sépales.
Comme le jeu de données est librement accessible et que c’est un très bon exemple, beaucoup de personnes l’utilisent pour leurs exemples ou leurs tests.
C’est un peu le “Hello world” du machine learning. Voici ce que donne une projection des données :
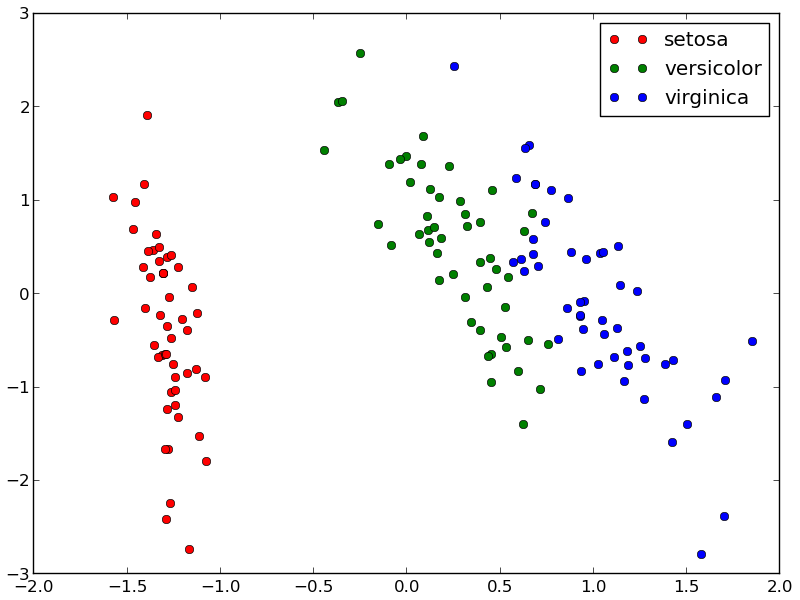
Comme on peut le remarquer, les différentes espèces d’iris sont identifiables par leurs caractéristiques. Les algorithmes devraient donc pouvoir assez bien s’en sortir. Un algorithme très simple est KNN pour K-nearest neighbor. L’idée est de calculer la distance entre l’iris à prédire et les iris des données d’apprentissage. La distance est simplement la [norme mathématique](https://fr.wikipedia.org/wiki/Norme_(math%C3%A9matiques){:target=”_blank”} étendue à plusieurs dimensions (4 dans notre exemple). On sélectionne les K éléments les plus proches. La prédiction sera alors l’espèce qui comporte le plus d’éléments parmi les K plus proches éléments. C’est aussi simple que ça. Voyons ce que ça donne niveau code :
def predictSpecie(dataset: List[Iris], k: Int, features: (Double, Double, Double, Double)) = {
dataset
.map(iris => (iris.distance(features), iris.getSpecie)).sorted.take(k) // calculate distance for each sample in dataset, sort by distance and take K nearest
.groupBy(_._2).map(elt => (elt._2.length, elt._1)).toList // group by specie, count occurences of species and transform map to list
.sortBy(-_._1).head._2 // sort descending by number of specie occurences, get the first one and return the specie name
}
Comme précédemment, pour ceux qui souhaitent tester (et je vous y encourage!) et ceux qui n’aiment pas trop scala, voici les versions complètes du programme en Java et en Scala avec le jeu de données associées (si vous avez besoin de précisions ou des questions, les commentaires sont là pour ça).
C’est bien de faire des prédictions mais c’est quand même mieux de savoir si elles sont justes ou pas.
J’ai donc ajouté la méthode evaluate pour tester la pertinence de l’algorithme. Comme on ne peut pas créer de nouvelles données
(comment savoir si l’algorithme se trompe si la donnée n’est pas en lien avec un véritable élément)
et qu’on ne peut pas tester son algorithme avec les données qui ont servi à l’apprentissage (trop facile !), il nous reste une dernière possibilité :
séparer les données en deux. La première partie servira à l’apprentissage et la seconde partie servira aux tests.
On teste différentes valeurs de K pour voir l’influence du paramètre. Dans notre cas, le taux d’erreur reste constant (aux alentours de 4%)
mais ce n’est pas nécessairement une généralité. Au passage, vous noterez que les jeux de données d’apprentissage et de test sont créés au hasard,
et les variations d’erreur peuvent être assez importantes en fonction de quels éléments sont sélectionnés dans l’un ou dans l’autre (entre 0 et 15%).
 D’ailleurs, avec ce constat, on pourrait s’arranger pour choisir un K et un jeu de données de départ pour avoir un taux d’erreur toujours égal à 0% !!!
Génial non ? Oui, mais non. Ce serait de l’overfitting. De l’over fit quoi ?
L’overfitting est le fait de “trop” paramétrer son algorithme par rapport au jeu de données utilisé pour tester.
Dans ce cas, l’algorithme n’est pas meilleur mais ses résultats pour le jeu de données de test continuent de s’améliorer.
Le risque est alors de penser que son algorithme est meilleur que ce qu’il est réellement
et dès que l’on essaiera de prédire de nouvelles données les résultats retomberont à leur niveau “normal”.
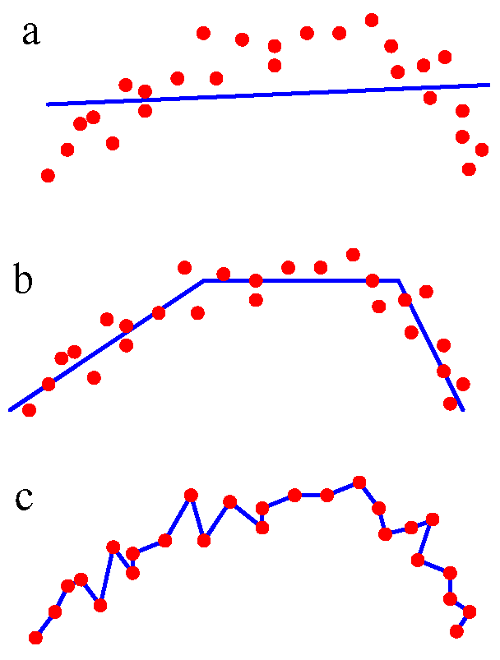
A l’inverse, l’underfitting c’est lorsque le modèle n’est pas suffisamment évolué pour modéliser les données.
On s’en rend généralement compte car les prédictions sont très mauvaises. Voici à droite une illustration de ces différents cas :
l’underfitting (a), l’overfitting (c) et un bon ajustement (b).
D’ailleurs, avec ce constat, on pourrait s’arranger pour choisir un K et un jeu de données de départ pour avoir un taux d’erreur toujours égal à 0% !!!
Génial non ? Oui, mais non. Ce serait de l’overfitting. De l’over fit quoi ?
L’overfitting est le fait de “trop” paramétrer son algorithme par rapport au jeu de données utilisé pour tester.
Dans ce cas, l’algorithme n’est pas meilleur mais ses résultats pour le jeu de données de test continuent de s’améliorer.
Le risque est alors de penser que son algorithme est meilleur que ce qu’il est réellement
et dès que l’on essaiera de prédire de nouvelles données les résultats retomberont à leur niveau “normal”.
A l’inverse, l’underfitting c’est lorsque le modèle n’est pas suffisamment évolué pour modéliser les données.
On s’en rend généralement compte car les prédictions sont très mauvaises. Voici à droite une illustration de ces différents cas :
l’underfitting (a), l’overfitting (c) et un bon ajustement (b).
Peut-on tout apprendre ?
 Attention cependant, comme nous venons de le voir, le machine learning n’est pas non plus une boite noire magique qui permet de tout deviner et qui s’adapte à tout.
Si l’on souhaite faire des prédictions de bonne qualité, il y a certaines choses à prendre en compte.
Tout d’abord, il est nécessaire que les résultats que l’on souhaite prédire soient différentiables.
Pour le cas des iris, les groupes étaient distincts (pas de recouvrement) et pour les appartements on voit clairement la corrélation entre la taille et le prix.
Si ce n’est pas le cas, même les meilleurs algorithmes ne pourront rien faire.
Dans ce cas, il faut chercher la ou les features ou combinaison de features qui permettront d’avoir cette différentiation.
J’ai plusieurs fois entendu dire que les algorithmes ne jouaient qu’à 20% dans la qualité des prédictions, les 80% autres sont dûs à la qualité des données.
Dans le monde réel, les choses sont bien plus complexes que sur ces exemples car il peut y avoir des imprécisions sur les caractéristiques,
des erreurs dans la classification des données d’entrainement ou beaucoup d’autre choses qui rendront les prédictions moins évidentes.
Attention cependant, comme nous venons de le voir, le machine learning n’est pas non plus une boite noire magique qui permet de tout deviner et qui s’adapte à tout.
Si l’on souhaite faire des prédictions de bonne qualité, il y a certaines choses à prendre en compte.
Tout d’abord, il est nécessaire que les résultats que l’on souhaite prédire soient différentiables.
Pour le cas des iris, les groupes étaient distincts (pas de recouvrement) et pour les appartements on voit clairement la corrélation entre la taille et le prix.
Si ce n’est pas le cas, même les meilleurs algorithmes ne pourront rien faire.
Dans ce cas, il faut chercher la ou les features ou combinaison de features qui permettront d’avoir cette différentiation.
J’ai plusieurs fois entendu dire que les algorithmes ne jouaient qu’à 20% dans la qualité des prédictions, les 80% autres sont dûs à la qualité des données.
Dans le monde réel, les choses sont bien plus complexes que sur ces exemples car il peut y avoir des imprécisions sur les caractéristiques,
des erreurs dans la classification des données d’entrainement ou beaucoup d’autre choses qui rendront les prédictions moins évidentes.
Une autre limite du machine learning est que les algorithmes sont incapables d’extrapoler les données de manière fiable. Il est donc nécessaire de faire des prédictions uniquement sur le même domaine de données que celui utilisé pour l’apprentissage. Pour l’exemple des appartements, les prédictions pour le prix des appartements de grande taille peuvent être très mauvaises. De même, pour les classifications, il est important d’avoir suffisamment d’éléments de chaque classe. Imaginez qu’une des trois espèces d’iris soit très rare et qu’on ait qu’une seule donnée. La prédiction sera alors très peu fiable. Les algorithmes de machine learning ne permettent donc pas d’apprendre de nouvelles choses mais seulement d’automatiser des choses connues ou de mettre en évidence des relations.
Sur les limites du machine learning, je vous recommande le très bon article : why machine learning fails.
Pour ceux qui souhaitent aller plus loin et comprendre un peu mieux, voici quelques liens qui me semblent particulièrement intéressants :
- Baptème en machine learning par Louis Dorard aux HumanTalks de juin (13min)
- Machine learning way easier than it looks
- Machine learning appliqué à la détection de chats
J’espère que vous comprenez maintenant un peu mieux ce qu’est le machine learning, quels sont les grands principes qui sont derrière ainsi que les forces et limites de cette approche.
 Hi, I use 🍪 to know if I speak alone here or if you like my content, do not hesitate to come and say hi!
I understand and
Hi, I use 🍪 to know if I speak alone here or if you like my content, do not hesitate to come and say hi!
I understand and